Libre adaptation du très amusant et gratuit Pix2Pix online qui transforme un dessin au trait sommaire en une image peinte ou photographique! (by Christoffer Hesse )
Récemment, j'ai fait un portage Tensorflow de pix2pix par Isola et al, couvert dans l'article Image-to-Image Translation in Tensorflow(traduit plus bas) J'ai pris quelques modèles pré-entraînés et j'ai créé un site Web interactif pour les essayer. Le navigateur chrome est recommandé.
Le modèle pix2pix fonctionne en se basant sur des paires d'images telles que des étiquettes de façade de bâtiment pour en faire des façades, puis tente de générer l'image de sortie correspondante à partir de n'importe quelle image d'entrée que vous lui donnez. L'idée vient directement du papier pix2pix, (VO)ce qui est une bonne lecture. Crée au début pour des chats mais... :)
Le modèle pix2pix fonctionne en se basant sur des paires d'images telles que des étiquettes de façade de bâtiment pour en faire des façades, puis tente de générer l'image de sortie correspondante à partir de n'importe quelle image d'entrée que vous lui donnez. L'idée vient directement du papier pix2pix, (VO)ce qui est une bonne lecture. Crée au début pour des chats mais... :)
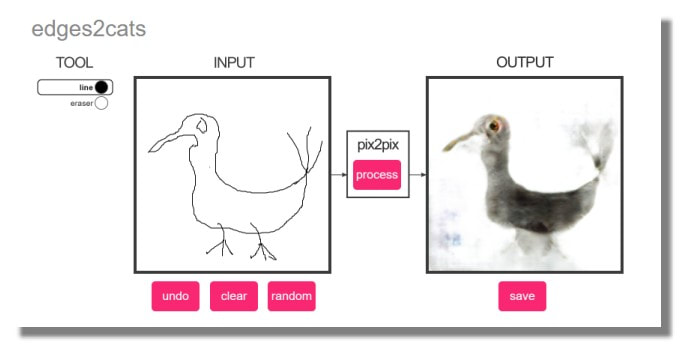
Reposant sur environ un stock de 2k de photos de chat et d'arêtes de bords générés automatiquement à partir de ces photos. Génère des objets de couleur chat, certains avec des visages de cauchemar. Le meilleur que j'ai vu jusqu'à présent était un poulpe de chat.
Certaines des photos ont l'air particulièrement effrayantes, je pense que c'est plus facile à remarquer quand un animal regarde mal, surtout autour des yeux. Les bords auto-détectés ne sont pas très bons et dans de nombreux cas n'ont pas détecté les yeux du chat, ce qui est un peu plus mauvais pour l'entraînement du modèle de traduction d'image.
Certaines des photos ont l'air particulièrement effrayantes, je pense que c'est plus facile à remarquer quand un animal regarde mal, surtout autour des yeux. Les bords auto-détectés ne sont pas très bons et dans de nombreux cas n'ont pas détecté les yeux du chat, ce qui est un peu plus mauvais pour l'entraînement du modèle de traduction d'image.
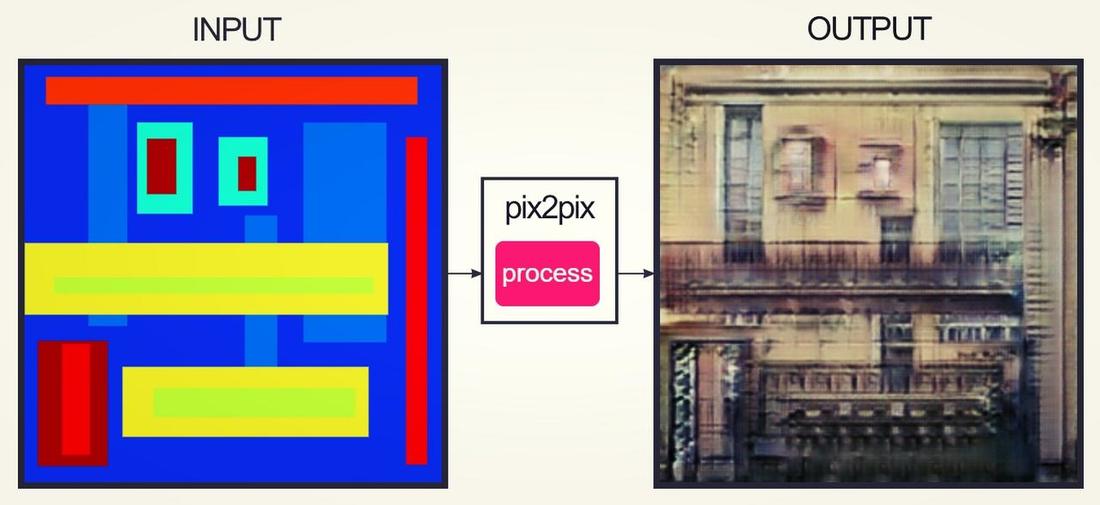
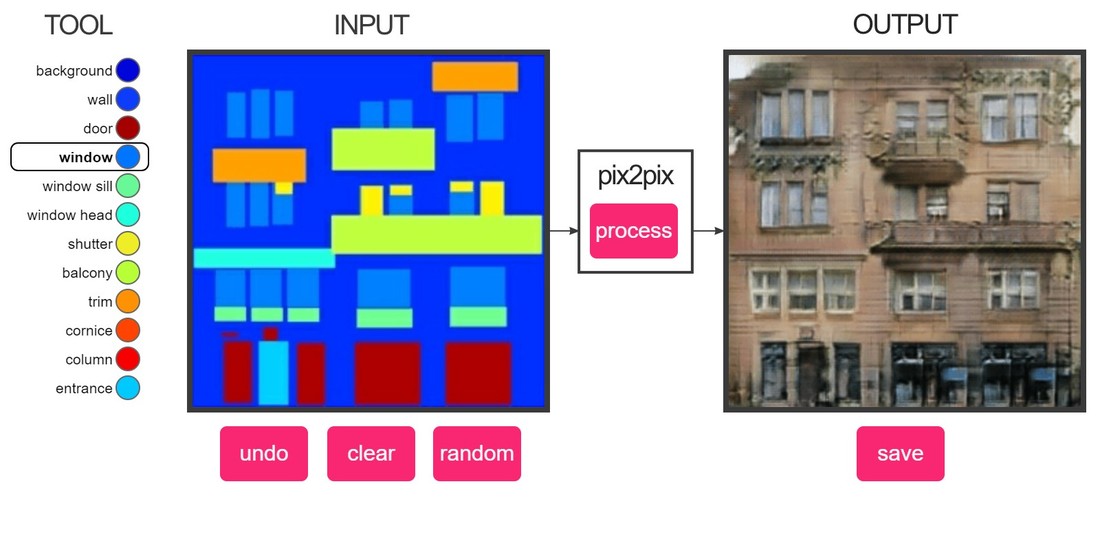
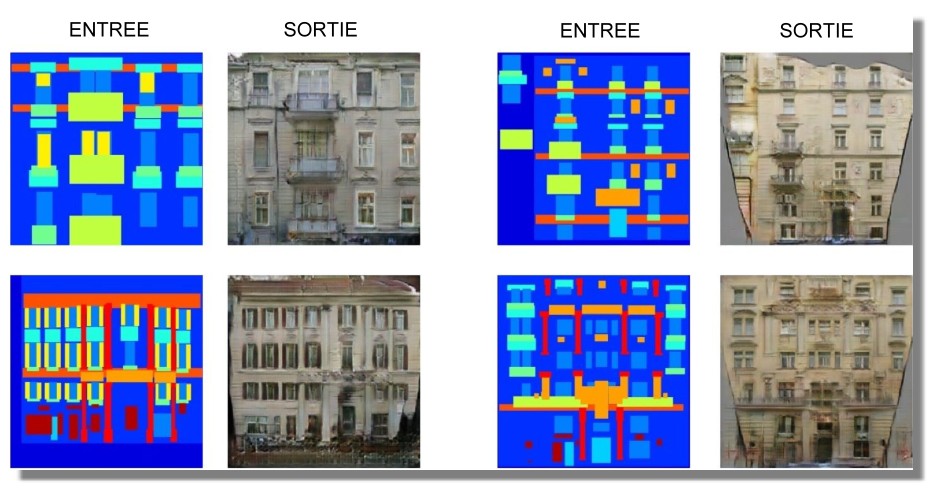
Formé sur une base de données de façades de bâtiments à des façades de bâtiments labellisées. Il ne semble pas sûr de ce qu'il faut faire avec une grande surface vide, mais si vous mettez suffisamment de fenêtres, cela donne souvent des résultats raisonnables. Dessinez des rectangles de couleur "mur" pour effacer les choses.
Je n'avais pas les noms des différentes parties des façades des bâtiments, alors j'ai deviné comment on les appelait.
Je n'avais pas les noms des différentes parties des façades des bâtiments, alors j'ai deviné comment on les appelait.
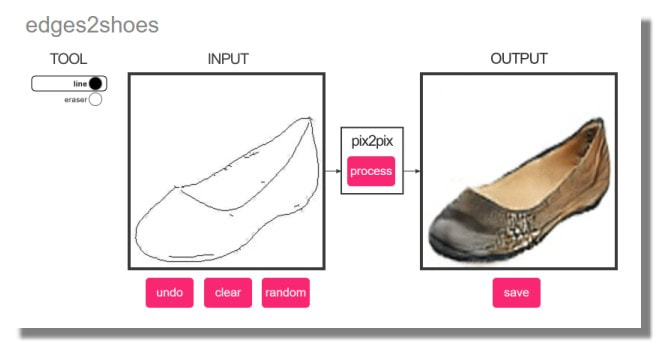
Formé sur une base de données de ~50k photos de chaussures collectées à partir de Zappos ainsi que des bords générés automatiquement à partir de ces photos. Si vous êtes vraiment bon pour dessiner les bords des chaussures, vous pouvez essayer de produire de nouveaux modèles. Gardez à l'esprit qu'il est formé sur des objets réels, donc si vous pouvez dessiner plus de choses en 3D, il semble fonctionner mieux.
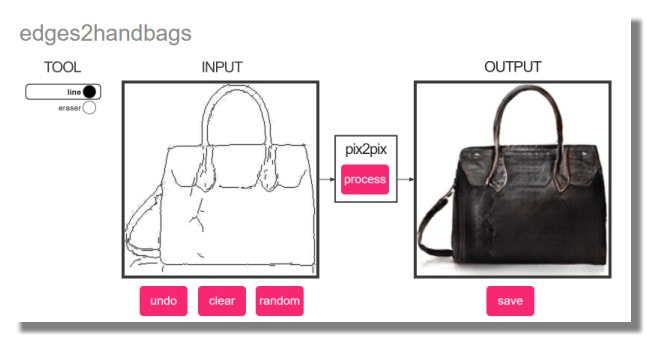
Similaire au précédent, formé sur une base de données de ~137k images de sacs à main collectées sur Amazon et générées automatiquement à partir de ces images. Si vous dessinez une chaussure ici au lieu d'un sac à main, vous obtenez une chaussure à la texture très étrange.
Les modèles ont été formés et exportés avec le script pix2pix.py de pix2pix-tensorflow. La démo interactive est réalisée en javascript à l'aide de l'API Canvas et exécute le modèle à l'aide de la section Datasets sur GitHub. Tous ceux qui ont été publiés en même temps que l'implémentation originale de pix2pix devraient être disponibles. Les modèles utilisés pour l'implémentation de javascript sont disponibles chez github.com/affinelayer/pix2pix-tensorflow-models.
Les bords pour les photos de chat ont été générés en utilisant Holistically-Nested Edge Detection et la fonctionnalité a été ajoutée à process.py et les dépendances ont été ajoutées aux l'images du Docker.
Les bords pour les photos de chat ont été générés en utilisant Holistically-Nested Edge Detection et la fonctionnalité a été ajoutée à process.py et les dépendances ont été ajoutées aux l'images du Docker.
La Théorie et la pratique
J'ai trouvé que les résultats de pix2pix d'Isola et al. avaient l'air plutôt cool et je voulais mettre en place un challenger sur le NET, alors j'ai porté le code Torch sur Tensorflow. L'implémentation en fichier unique est disponible sous forme de pix2pix-tensorflow sur github.
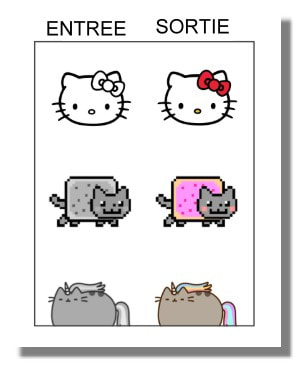
Voici quelques exemples de ce que cette chose fait, à partir du papier original :
Voici quelques exemples de ce que cette chose fait, à partir du papier original :

|
"La Pierre du Sorcier, un rocher aux pouvoirs énormes, tels que : le plomb en or, les chevaux en l'or, la vie immortelle, donnant aux fantômes des corps restaurés, des bouts de trolls, des trolls en or, etc."
D'après Wizard People, Dear Readers
Pix2pix ne donnera probablement pas de corps restaurés de fantômes, mais si vous avez un ensemble de données de chevaux normaux et leurs formes dorées correspondantes, il peut être capable de faire quelque chose avec cela. |
Le Code
# make sure you have Tensorflow 0.12.1 installed first
python -c "import tensorflow; print(tensorflow.__version__)"
# clone the repo
git clone https://github.com/affinelayer/pix2pix-tensorflow.git
cd pix2pix-tensorflow
# download the CMP Facades dataset http://cmp.felk.cvut.cz/~tylecr1/facade/
python tools/download-dataset.py facades
# train the model
# this may take 1-9 hours depending on GPU, on CPU you will be waiting for a bit
python pix2pix.py \
--mode train \
--output_dir facades_train \
--max_epochs 200 \
--input_dir facades/train \
--which_direction BtoA
# test the model
python pix2pix.py \
--mode test \
--output_dir facades_test \
--input_dir facades/val \
--checkpoint facades_train
python -c "import tensorflow; print(tensorflow.__version__)"
# clone the repo
git clone https://github.com/affinelayer/pix2pix-tensorflow.git
cd pix2pix-tensorflow
# download the CMP Facades dataset http://cmp.felk.cvut.cz/~tylecr1/facade/
python tools/download-dataset.py facades
# train the model
# this may take 1-9 hours depending on GPU, on CPU you will be waiting for a bit
python pix2pix.py \
--mode train \
--output_dir facades_train \
--max_epochs 200 \
--input_dir facades/train \
--which_direction BtoA
# test the model
python pix2pix.py \
--mode test \
--output_dir facades_test \
--input_dir facades/val \
--checkpoint facades_train
Après une longue période d'entraînement, vous pouvez vous attendre à des résultats de ce style :
Comment Pix2pix fonctionne
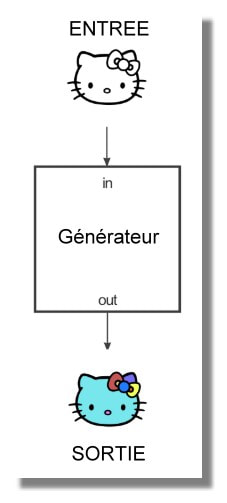
Pix2pix utilise un réseau contradictoire génératif conditionnel (cGAN) pour apprendre un mappage d'une image d'entrée à une image de sortie.
Le réseau est composé de deux pièces principales, le Générateur et le Discriminateur. Le Générateur applique une certaine transformation à l'image d'entrée pour obtenir l'image de sortie. Le Discriminateur compare l'image d'entrée à une image inconnue (soit une image cible de l'ensemble de données ou une image de sortie du générateur) et essaie de deviner si celle-ci a été produite par le générateur.
Un exemple d'ensemble de données serait que l'image d'entrée est une image en noir et blanc et que l'image cible est la version couleur de l'image :
Le réseau est composé de deux pièces principales, le Générateur et le Discriminateur. Le Générateur applique une certaine transformation à l'image d'entrée pour obtenir l'image de sortie. Le Discriminateur compare l'image d'entrée à une image inconnue (soit une image cible de l'ensemble de données ou une image de sortie du générateur) et essaie de deviner si celle-ci a été produite par le générateur.
Un exemple d'ensemble de données serait que l'image d'entrée est une image en noir et blanc et que l'image cible est la version couleur de l'image :
Dans ce cas, le générateur essaie d'apprendre à colorier une image en noir et blanc :
|
|
Le discriminateur examine les tentatives de colorisation du générateur et essaie d'apprendre à faire la différence entre les colorisations fournies par le générateur et l'image cible colorisée réelle fournie dans l'ensemble de données.
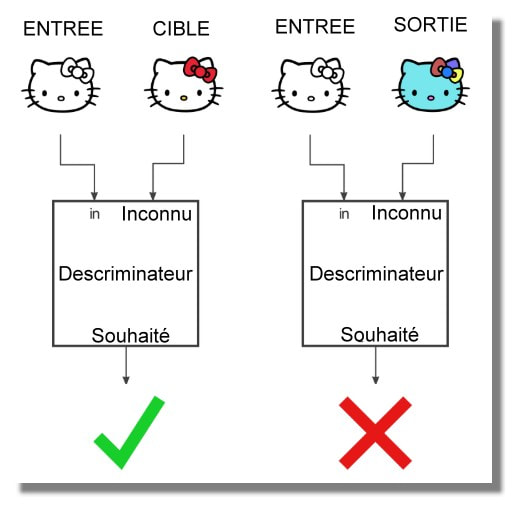
Pourquoi se donner tant de mal ? L'un des principaux points du document est que le discriminateur fournit une fonction de perte pour l'entraînement de votre générateur et que vous n'avez pas eu à le spécifier manuellement, ce qui est vraiment soigné. Le code de transformation conçu à la main a été remplacé par des réseaux neuronaux de formation, alors pourquoi ne pas remplacer également les calculs de perte réalisés à la main ? Si cela fonctionne, vous pouvez laisser l'ordinateur faire le travail pendant que vous vous détendez dans le confort et craignez que les ordinateurs remplacent votre travail.
Examinons les deux parties du réseau accusatoire : le Générateur et le Discriminateur.
Le Générateur
Le Générateur a la tâche de prendre une image d'entrée et d'effectuer la transformation que nous voulons afin de produire l'image cible. Un exemple d'entrée serait une image en noir et blanc, et nous voulons que la sortie soit une version colorisée de cette image. La structure du générateur est appelée "encodeur-décodeur" et dans pix2pix, l'encodeur-décodeur ressemble plus ou moins à ceci :
Examinons les deux parties du réseau accusatoire : le Générateur et le Discriminateur.
Le Générateur
Le Générateur a la tâche de prendre une image d'entrée et d'effectuer la transformation que nous voulons afin de produire l'image cible. Un exemple d'entrée serait une image en noir et blanc, et nous voulons que la sortie soit une version colorisée de cette image. La structure du générateur est appelée "encodeur-décodeur" et dans pix2pix, l'encodeur-décodeur ressemble plus ou moins à ceci :
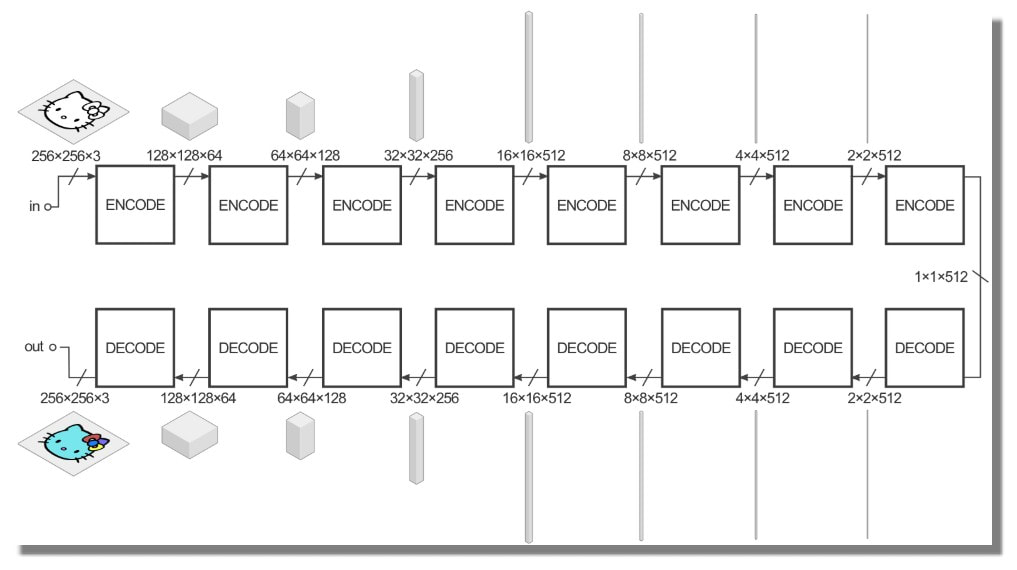
Les volumes sont là pour vous donner une idée de la forme des dimensions des tenseurs à côté d'eux. L'entrée dans cet exemple est une image 256x256 avec 3 canaux de couleur (rouge, vert et bleu, tous égaux pour une image en noir et blanc), et la sortie est la même.
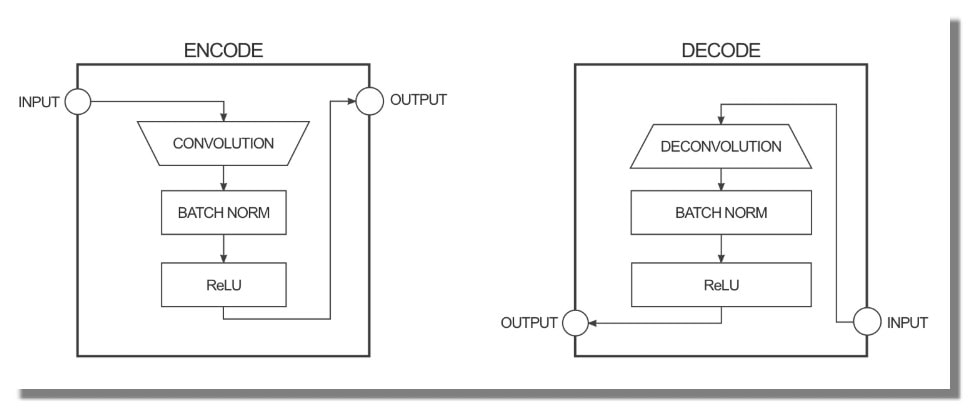
Le générateur prend quelques entrées et essaie de les réduire avec une série de codeurs (convolution + fonction d'activation) en une représentation beaucoup plus petite. L'idée est qu'en le comprimant de cette façon, nous espérons avoir une représentation de niveau supérieur des données après la couche d'encodage finale. Les couches de décodage font l'inverse (déconvolution + fonction d'activation) et inversent l'action des couches codeur.
Le générateur prend quelques entrées et essaie de les réduire avec une série de codeurs (convolution + fonction d'activation) en une représentation beaucoup plus petite. L'idée est qu'en le comprimant de cette façon, nous espérons avoir une représentation de niveau supérieur des données après la couche d'encodage finale. Les couches de décodage font l'inverse (déconvolution + fonction d'activation) et inversent l'action des couches codeur.
Afin d'améliorer la performance de la transformation d'image à image dans le papier, les auteurs ont utilisé un "U-Net" au lieu d'un encodeur-décodeur. C'est la même chose, mais avec des "skip connections" connectant directement les couches codeur aux couches décodeur :
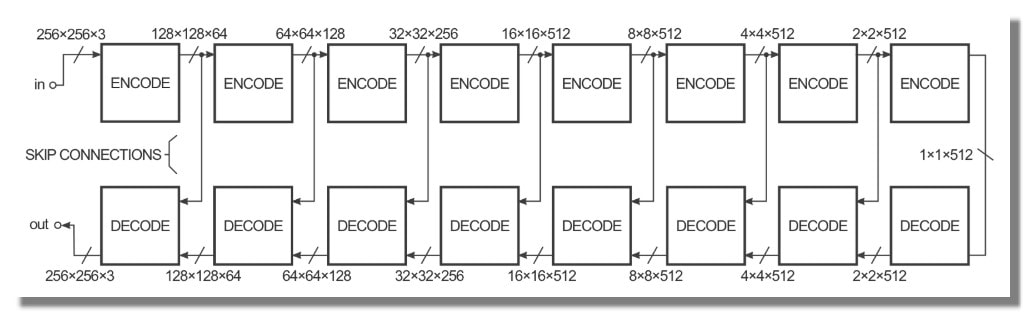
Les "skip connections" donnent au réseau l'option de contourner la partie encodage/décodage si elle n'a pas d'utilité.
Ces diagrammes sont une légère simplification. Par exemple, la première et la dernière couche du réseau n'ont pas de couche de norme de lot et quelques couches du milieu ont des unités d'abandon. Le mode de colorisation utilisé dans le papier a également un nombre différent de canaux pour les couches d'entrée et de sortie.
Ces diagrammes sont une légère simplification. Par exemple, la première et la dernière couche du réseau n'ont pas de couche de norme de lot et quelques couches du milieu ont des unités d'abandon. Le mode de colorisation utilisé dans le papier a également un nombre différent de canaux pour les couches d'entrée et de sortie.
Le Descriminateur
Le Discriminateur a pour tâche de prendre deux images, une image d'entrée et une image inconnue (qui sera soit une image cible ou une image de sortie du générateur), et de décider si la deuxième image a été produite par le générateur ou non.

La structure ressemble beaucoup à la section codeur du générateur, mais fonctionne un peu différemment. La sortie est une image 30x30 où chaque valeur de pixel (0 à 1) représente la crédibilité de la section correspondante de l'image inconnue. Dans l'implémentation Pix2pix, chaque pixel de cette image 30x30 correspond à la crédibilité d'un patch 70x70 de l'image d'entrée (les patchs se chevauchent beaucoup puisque les images d'entrée sont 256x256). L'architecture est appelée "PatchGAN".
Formation
Pour former ce réseau, il y a deux étapes : la formation du discriminateur et la formation du générateur.
Pour former le discriminateur, le générateur génère d'abord une image de sortie. Le discriminateur examine la paire entrée/cible et la paire entrée/sortie et produit ses suppositions sur le réalisme de la paire entrée/sortie. Les poids du discriminateur sont ensuite ajustés en fonction de l'erreur de classification de la paire entrée/sortie et de la paire entrée/cible.
Formation
Pour former ce réseau, il y a deux étapes : la formation du discriminateur et la formation du générateur.
Pour former le discriminateur, le générateur génère d'abord une image de sortie. Le discriminateur examine la paire entrée/cible et la paire entrée/sortie et produit ses suppositions sur le réalisme de la paire entrée/sortie. Les poids du discriminateur sont ensuite ajustés en fonction de l'erreur de classification de la paire entrée/sortie et de la paire entrée/cible.
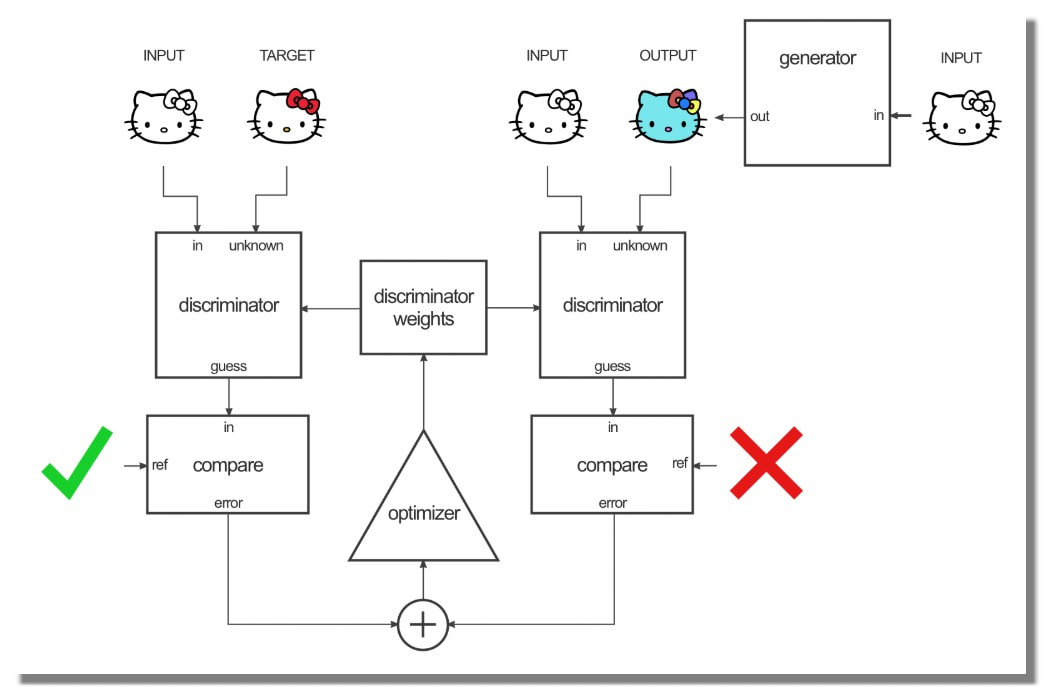
Les poids du générateur sont ensuite ajustés en fonction de la sortie du discriminateur ainsi que de la différence entre la sortie et l'image cible.
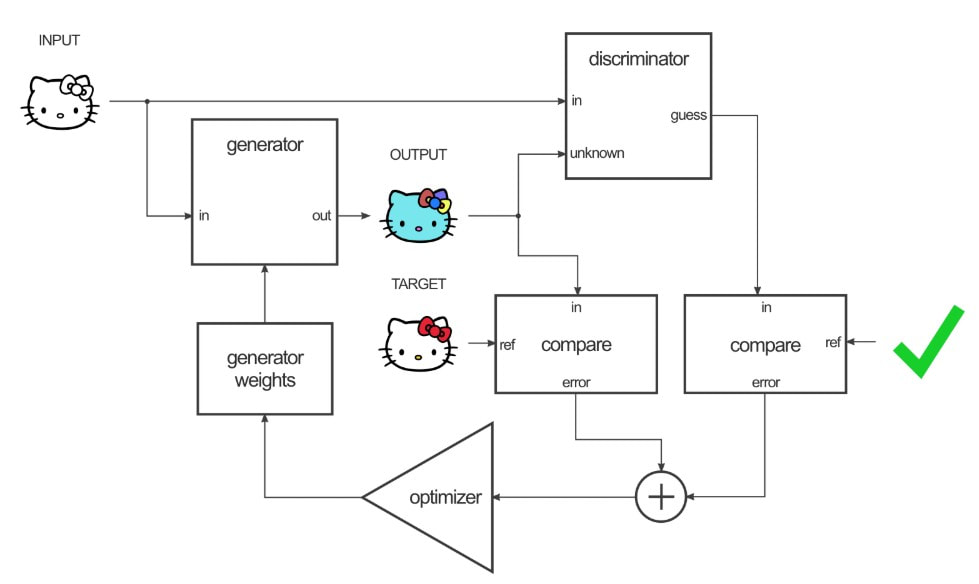
Le truc astucieux ici, c'est que lorsque vous formez le générateur sur la sortie du discriminateur, vous calculez en fait les gradients à travers le discriminateur, ce qui signifie que pendant que le discriminateur s'améliore, vous formez le générateur pour battre le discriminateur.
La théorie est que plus le discriminateur s'améliore, plus le générateur s'améliore. Si le discriminateur est bon dans son travail et que le générateur est capable d'apprendre la fonction de mappage correcte grâce à la descente de gradient, vous devriez obtenir des sorties générées qui pourraient tromper un humain.
La théorie est que plus le discriminateur s'améliore, plus le générateur s'améliore. Si le discriminateur est bon dans son travail et que le générateur est capable d'apprendre la fonction de mappage correcte grâce à la descente de gradient, vous devriez obtenir des sorties générées qui pourraient tromper un humain.
Validation
La validation du code a été effectuée sur une machine Linux avec un GPU ~1.3 TFLOPS Nvidia GTX 750 Ti. En raison d'un manque de puissance de calcul, la validation n'est pas étendue et seul l'ensemble de données des façades à 200 époques a été testé.
Le Code
git clone https://github.com/affinelayer/pix2pix-tensorflow.git
cd pix2pix-tensorflow
python tools/download-dataset.py facades
sudo nvidia-docker run \
--volume $PWD:/prj \
--workdir /prj \
--env PYTHONUNBUFFERED=x \
affinelayer/pix2pix-tensorflow \
python pix2pix.py \
--mode train \
--output_dir facades_train \
--max_epochs 200 \
--input_dir facades/train \
--which_direction BtoA
sudo nvidia-docker run \
--volume $PWD:/prj \
--workdir /prj \
--env PYTHONUNBUFFERED=x \
affinelayer/pix2pix-tensorflow \
python pix2pix.py \
--mode test \
--output_dir facades_test \
--input_dir facades/val \
--checkpoint facades_train
cd pix2pix-tensorflow
python tools/download-dataset.py facades
sudo nvidia-docker run \
--volume $PWD:/prj \
--workdir /prj \
--env PYTHONUNBUFFERED=x \
affinelayer/pix2pix-tensorflow \
python pix2pix.py \
--mode train \
--output_dir facades_train \
--max_epochs 200 \
--input_dir facades/train \
--which_direction BtoA
sudo nvidia-docker run \
--volume $PWD:/prj \
--workdir /prj \
--env PYTHONUNBUFFERED=x \
affinelayer/pix2pix-tensorflow \
python pix2pix.py \
--mode test \
--output_dir facades_test \
--input_dir facades/val \
--checkpoint facades_train
Pour comparaison, la première image de l'ensemble de validation ressemble à ceci :

Implémentation
L'implémentation est un fichier unique, pix2pix.py, qui se fait autant que possible à l'intérieur du graphique Tensorflow.
Le processus de portage consistait principalement à examiner l'implémentation existante de Torch ainsi que le code source de Torch pour déterminer quels types de couches et de paramètres étaient utilisés afin de rendre la version de Tensorflow aussi fidèle que possible à l'original. Debugger une implémentation cassée peut prendre du temps, donc j'ai essayé d'être prudent au sujet de la conversion pour éviter d'avoir à faire du débogage extensif.
La mise en œuvre a commencé par la création du graphique du générateur, puis du graphique discriminateur, puis du système de formation. Le générateur et le graphique discriminateur ont été imprimés au moment de l'exécution à l'aide du code Torch pix2pix. J'ai regardé dans les sources du framework Torch pour les différents types de couches et j'ai trouvé quels paramètres et opérations étaient présents et implémenté ceux de Tensorflow.
Idéalement, j'aurais pu exporter les poids du réseau entraînés pix2pix dans Tensorflow pour vérifier la construction du graphique, mais c'était assez ennuyeux, et je suis assez mauvais en Torch, donc je ne l'ai pas fait.
La plupart des bogues dans mon code étaient liés au modèle build-graph-then-execute de Tensorflow, ce qui peut être un peu surprenant quand on est habitué au code impératif.
tous les échantillons de code sur ce site sont dans le domaine public, à moins d'indication contraire.
Le processus de portage consistait principalement à examiner l'implémentation existante de Torch ainsi que le code source de Torch pour déterminer quels types de couches et de paramètres étaient utilisés afin de rendre la version de Tensorflow aussi fidèle que possible à l'original. Debugger une implémentation cassée peut prendre du temps, donc j'ai essayé d'être prudent au sujet de la conversion pour éviter d'avoir à faire du débogage extensif.
La mise en œuvre a commencé par la création du graphique du générateur, puis du graphique discriminateur, puis du système de formation. Le générateur et le graphique discriminateur ont été imprimés au moment de l'exécution à l'aide du code Torch pix2pix. J'ai regardé dans les sources du framework Torch pour les différents types de couches et j'ai trouvé quels paramètres et opérations étaient présents et implémenté ceux de Tensorflow.
Idéalement, j'aurais pu exporter les poids du réseau entraînés pix2pix dans Tensorflow pour vérifier la construction du graphique, mais c'était assez ennuyeux, et je suis assez mauvais en Torch, donc je ne l'ai pas fait.
La plupart des bogues dans mon code étaient liés au modèle build-graph-then-execute de Tensorflow, ce qui peut être un peu surprenant quand on est habitué au code impératif.
tous les échantillons de code sur ce site sont dans le domaine public, à moins d'indication contraire.